
Promt based database management sounds like magic. But does it actually work in an open-source database like PostgreSQL? We explored the answer so your engineering team doesn’t have to waste hours experimenting blindly.
Between performance issues, unclear responsibilities and constant context-switching, there’s little time to explore every promising new tool. Especially if someone on your team has accidentally ended up with the DBA hat. So we took one of the most promising developments - the Model Context Protocol - and tested it across two PostgreSQL setups.
Tools like MCP don’t replace solid database management but they can speed up diagnostics, give developers quicker insights, and help DBAs scale their impact.
In this blog you'll learn what worked, what didn’t, and what to watch out for.
MCP stands for Model Context Protocol and was introduced in late 2024 as an open standard by Anthropic. Think of it as your AI assistant’s backstage pass to your data : the protocol connects your database to an LLM like Claude, Gemini, Cursor or another AI assistant. It allows you to ask questions about your data or infrastructure in natural language.
Each MCP comes with its own scope and built-in “tools.” These tools function like APIs: they let the LLM run queries, analyze workloads, or assess your database health. What your assistant can actually do depends entirely on the MCP you choose.
For PostgreSQL, we used both CrystalDBA MCP Pro combined with Cursor, and Dreambase’s built-in MCP integration on Supabase.
To test the MCP, we built a small PostgreSQL database around a fictional dataset of pumpkin growers, including the seeds they used and the competitions they attended. Not exactly enterprise data, but perfect for testing joins, sorting and data modeling.
We asked the same question each time:
“Who grew the heaviest pumpkin, and which seed did they use?”
We ran the test across two different setups:
All PostgreSQL setups returned the correct answer: a joined dataset showing the grower’s name, the weight, and the seed type.
“The heaviest pumpkin was grown by <name of grower> and it weighed 1160kg. The seed used was “<seed name>” (from the year 2024).”
Dreambase even offered extra insights, like:
Naming matters. A lot. This only worked because our table and column names were clear. Clear naming is always good practice, but for AI-driven tools, it’s essential. LLMs infer intent based on table and column names - vague or cryptic structures are a fast track to confusion.
We didn’t stop at data questions. We also asked both MCPs to answer management-level prompts like:
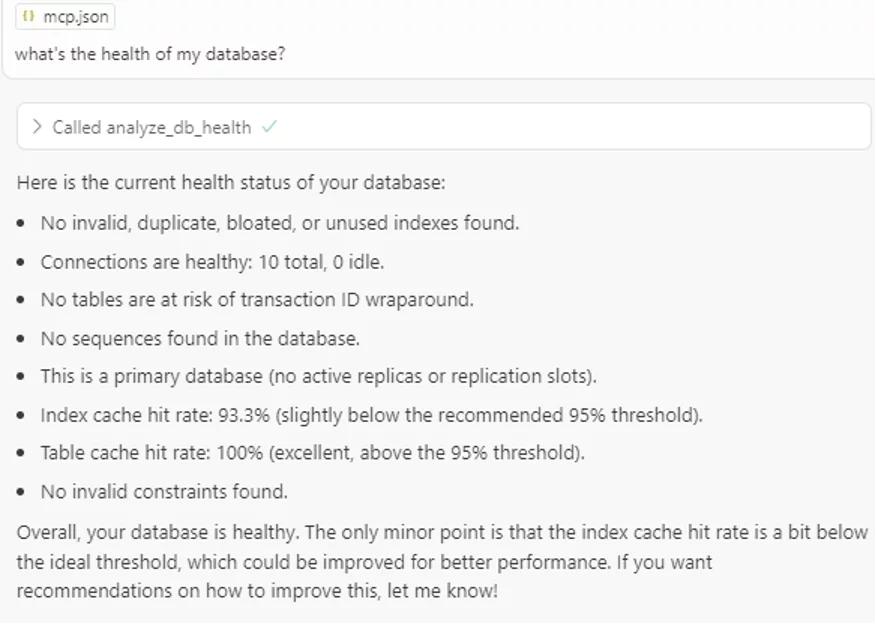
"What’s the health of my database?"
"What are the top statements running right now?"
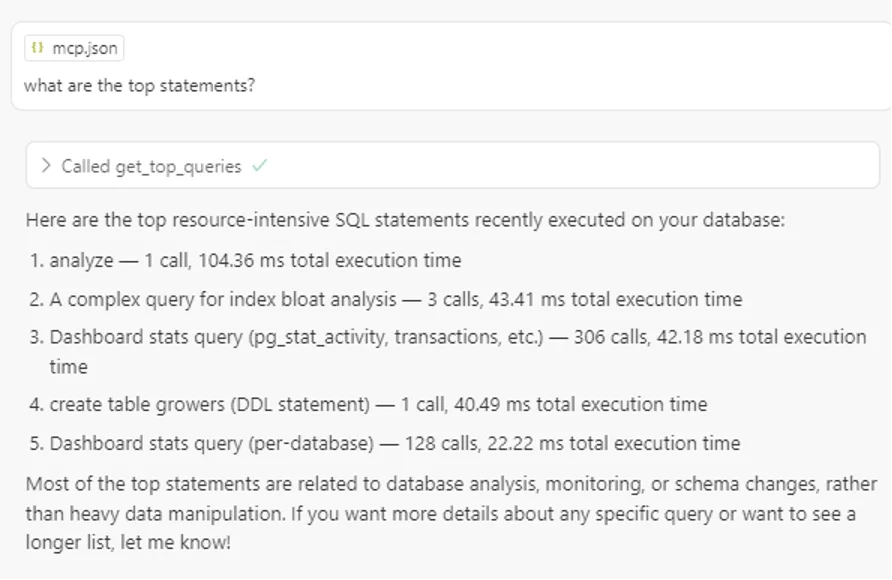
With CrystalDBA MCP Pro, the results were strong: the LLM was able to call structured tools built into the MCP, delivering actionable insights on query load, slow statements, and workload patterns.
At our parent company Monin, a similar test was performed on Oracle using SQLcl. The contrast was striking. Without integrated tools, the LLM could only guess which SQL statements to run, often producing vague or unhelpful answers.
That’s when the importance of built-in tooling becomes clear:
With CrystalDBA MCP Pro, the LLM called structured tools built into the MCP. That gave us actual insights on query load, bottlenecks, and workload patterns.
✅ Takeaway: If the MCP includes structured tools for monitoring, you get usable answers.
❌ If not, your LLM might just make something up that sounds reasonable but isn’t correct
How does this compare to a real PostgreSQL health check?
At Hieda, we benchmarked the MCP output against our own PostgreSQL health checklist.
While CrystalDBA covers core metrics like top statements and basic load analysis, it doesn’t (yet) surface things like index usage, autovacuum stats or cache efficiency.
Is someone on your team suddenly in charge of the database, just because no one else stepped up? Then this kind of tool probably sounds like a dream.
But this is the truth:
MCP is not a shortcut. It’s an amplifier - of what’s working, or what’s already broken.
So if you’re exploring PostgreSQL MCPs, make sure:
1. Check the prerequisites
Your MCP might need specific extensions or packages to work properly.
For PostgreSQL, pg_stat_statements is a must — others like hypopg may be required too.
2. Never test this on production
Hooking your MCP into a live database is asking for trouble.
Use a non-production environment with a well-defined dataset.
3. Limit what the LLM can access
Grant read-only access to a restricted database user.
Don’t expose sensitive views, and make sure everything is properly audited.
4. Make naming count
LLMs infer meaning from your naming conventions.
If your columns are named data1 and val_b, your results will reflect that. Poorly.
5. Understand how it behaves
Most MCPs have built-in tools to inspect metrics or run diagnostics.
If those tools are missing, the LLM will generate raw SQL — not always accurately.
A quick note on performance
On our test databases, the performance impact was negligible — the MCP simply issues SQL statements like any user would. But on large, poorly indexed databases, even simple queries can trigger expensive scans. So keep it light, scoped, and preferably off PROD.
PostgreSQL MCPs like CrystalDBA show real promise especially in dev and test environments where structure is clear and access is controlled. But they’re not a fix for deeper issues like unclear ownership or messy database design.
At Hieda, we test these tools so you don’t have to. Want to experiment safely, or unsure whether your environment is ready for AI-driven workflows? We’ll help you assess, prepare, and avoid costly surprises so your team can move faster without losing control.


