
You can automate every build, every test, every deployment but when the database fails, everything fails with it.
For years, databases have stayed the most manual part of the stack, guarded by a handful of experts, managed through instinct and scripts.
Meanwhile, everything else evolved: infrastructure turned into code, CI/CD pipelines took over, and observability became standard.
Database Reliability Engineering (DBRE) is what happens when that gap finally closes. It might sound like just another buzzword. For us, it’s DevOps for databases.
In this blog, we’ll talk about the six foundations of database reliability engineering in practice.
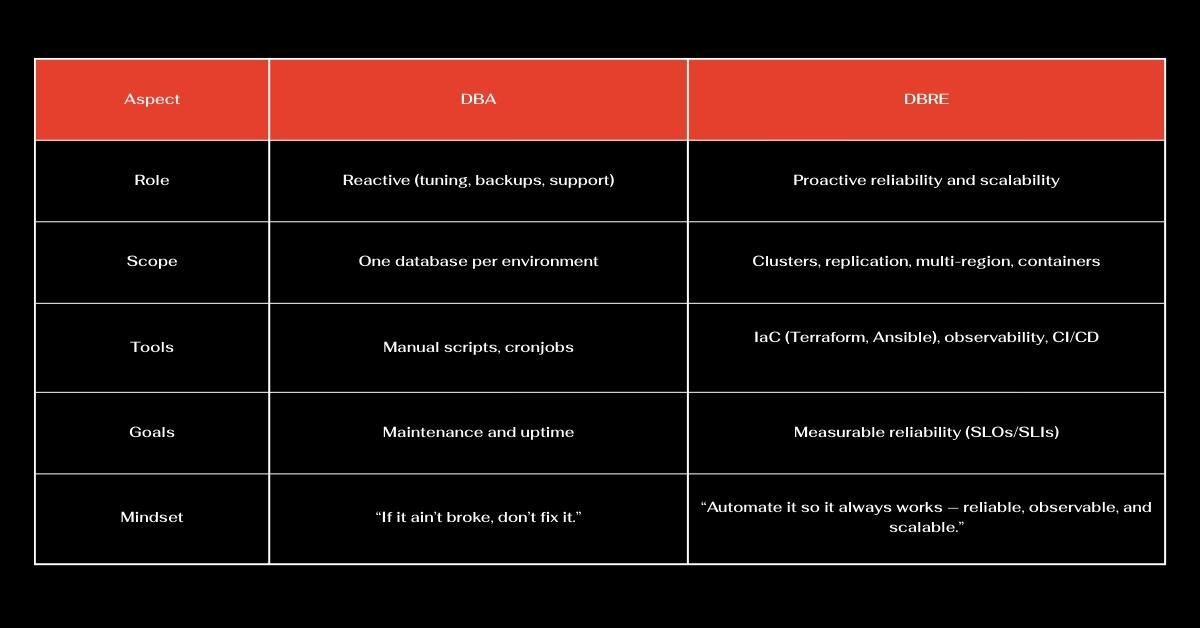
The story of DBRE starts with the DBA and the hard-earned lessons that role brought. DBAs have always been the guardians of data integrity and stability. They understand the systems that everyone else takes for granted, and they know exactly what happens when something breaks.
That deep operational knowledge is still essential today.
What’s changed is the environment around it. Modern teams deploy daily, across multiple regions and clouds. Infrastructure scales automatically, and downtime just isn’t acceptable.
Reliability can’t depend on manual effort, it has to be designed in from the start.
That’s the essence of DBRE: taking the precision and accountability of a great DBA, and amplifying it with automation, observability, and version control.
Let’s make it concrete: Imagine managing 50+ PostgreSQL clusters in a high-availability setup, spread across data centres or cloud environments.
Every node, replica and backup has to behave predictably, especially when something fails.
At Hieda, we’ve seen that reliability at this scale always rests on the same foundations: six building blocks that bring structure and confidence to every PostgreSQL environment.
Declarative setups are the foundation of reliable infrastructure. DBRE teams define their PostgreSQL clusters as code using Terraform, Ansible, … That way, every environment can be rebuilt in minutes, not hours.
For Kubernetes environments, operators like i.e. CloudNativePG or CrunchyData Postgres Operator handle provisioning, replication, and storage management automatically.
Backups are only as good as the last time you restored them. It’s a sentence you’ve probably heard more than once.
You shouldn’t just schedule backups, you need to verify them.
The most important step is automation. Running restore tests manually once a quarter won’t cut it, they need to happen continuously.
That’s where tools like pgBackRest can make the difference: automated restore testing verifies every night that a backup can actually be recovered on a clean node, so you know your recovery time and data integrity before it ever matters.
High availability (HA) is the heartbeat of reliability.
Where DBAs used to manually promote replicas, DBRE setups automate the process entirely.
Tools like Patroni, EDB Failover Manager, repmgr, or CloudNativePG constantly monitor cluster health.
If the primary node fails, a replica is promoted automatically, connected services are re-routed, and the cluster heals itself, predictably and without data loss.
A great metric to track for high availability is MTTR (mean time to recovery): how fast can the system heal itself, and how much of that process is automated?
Every iteration makes recovery faster and less dependent on people.
You can’t improve what you can’t see. Another cliché that people nod at enthusiastically but most of the time haven’t implemented.
Reliable systems depend on observability: knowing what’s happening long before users notice. You should build a monitoring stack that combines depth with clarity.
Key PostgreSQL metrics include:
A strong DBRE dashboard isn’t just to visualize infrastructure data. Connect it to service objectives like “95 % of queries under 200 ms.” That’s how observability becomes part of decision-making.
Databases should follow the same delivery lifecycle as applications. Instead of running manual SQL scripts, think about integrating schema changes directly into CI/CD pipelines using Liquibase or Flyway, deployed via ArgoCD or GitHub Actions, and governed through GitOps.
They enforce guardrails like:
This makes schema management predictable and keeps changes safe even under pressure.
You can’t call a system reliable if anyone can break it, access data they shouldn’t, or change configurations without traceability.
That’s why security is part of reliability by design:
Let’s map this on a real life use case: a government platform manages 34 EDB Advanced Server clusters
in high-availability configuration across multiple environments.
Their DBRE setup:
A small DBRE team now manages dozens of environments without manual intervention.
And the results speak for themselves:
When these six foundations are in place, reliability stops being an assumption. It becomes something you can measure, improve, and prove.
Think about Service Level Indicators (SLIs) such as:
And track Service Level Objectives (SLOs) like:
These metrics show when to scale, when to optimise, and when to automate. The Six Building Blocks of DBRE: DevOps for Databases
If you mention DevOps in databases, you just need to talk about the cultural part too. Developers want speed. Ops wants stability. With database reliability engineering we give them both a shared language: schema-as-code, automated reviews, and predictable deployments.
It’s how you stop developers from becoming accidental DBAs, and how you turn “don’t touch it” into “let’s test it.”
And if this blog feels overwhelming, you should keep another DevOps principle in mind: start small. Automate one backup, track one metric, test one restore. Each step adds predictability and that’s what reliability really is.
And if you need some help, Hieda can always help!


